Deployment wieloregionowy przy użyciu AWS CodePipeline
Proces wdrożenia to jeden z kluczowych etapów cyklu życia oprogramowania. Obejmuje instalację, konfigurację i dostosowanie aplikacji do środowiska docelowego. Aby uprościć i zautomatyzować ten proces, warto wykorzystać usługi DevOps oferowane przez AWS, takie jak AWS CodeDeploy, AWS CloudFormation, Amazon S3, a przede wszystkim AWS CodePipeline, który jest głównym tematem.
 AWS CodeDeploy – to usługa, która automatyzuje wdrażanie oprogramowania do różnych usług obliczeniowych, takich jak Amazon EC2, AWS Lambda i serwerów on-premise.
AWS CodeDeploy – to usługa, która automatyzuje wdrażanie oprogramowania do różnych usług obliczeniowych, takich jak Amazon EC2, AWS Lambda i serwerów on-premise.
![]() AWS CloudFormation – zapewnia wspólny język do opisywania i dostarczania wszystkich zasobów infrastruktury w środowisku chmury.
AWS CloudFormation – zapewnia wspólny język do opisywania i dostarczania wszystkich zasobów infrastruktury w środowisku chmury.
![]() Amazon S3 – to prosty interfejs usługi internetowej, którego można używać do przechowywania i pobierania dowolnej ilości danych, w dowolnym czasie i z dowolnego miejsca w sieci.
Amazon S3 – to prosty interfejs usługi internetowej, którego można używać do przechowywania i pobierania dowolnej ilości danych, w dowolnym czasie i z dowolnego miejsca w sieci.
![]() AWS CodePipeline – to w pełni zarządzana usługa pozwalająca na automatyzację pipeline’ów, w celu szybkich i niezawodnych aktualizacji aplikacji i infrastruktury. Dzięki możliwości obsługiwania działań między regionami AWS, umożliwia wdrożenie aplikacji za pomocą pojedynczego pipeline’u, w wielu regionach. Ma to wpływ nie tylko na dostępność aplikacji, ale również opóźnienia z nią powiązane.
AWS CodePipeline – to w pełni zarządzana usługa pozwalająca na automatyzację pipeline’ów, w celu szybkich i niezawodnych aktualizacji aplikacji i infrastruktury. Dzięki możliwości obsługiwania działań między regionami AWS, umożliwia wdrożenie aplikacji za pomocą pojedynczego pipeline’u, w wielu regionach. Ma to wpływ nie tylko na dostępność aplikacji, ale również opóźnienia z nią powiązane.
Jak działa AWS CodePipeline?
AWS CodePipeline to w pełni zarządzana usługa pozwalająca na automatyzację pipeline’ów, w celu szybkich i niezawodnych aktualizacji aplikacji i infrastruktury. Dzięki możliwości obsługiwania działań między regionami AWS, umożliwia wdrożenie aplikacji za pomocą pojedynczego pipeline’u, w wielu regionach. Ma to wpływ nie tylko na dostępność aplikacji, ale również opóźnienia z nią powiązane. To narzędzie wspiera continuous deployment, czyli ciągłe wdrażanie.
Usługa dzieli cały workflow na poszczególne etapy. Przykładem może być etap budowy, podczas którego napisany kod jest uruchamiany i testowany. Innym przykładem może być etap deploymentu, w którym aktualizacje są wdrażane na środowisko produkcyjne. Każdy element procesu można oznaczyć, w celu lepszego śledzenia, kontroli i raportowania jego przebiegu.
Każdy pipeline zawiera co najmniej jedną akcję (działanie wykonywane na artefakcie). Działania pipeline’owe są wykonywane w określonej kolejności; sekwencyjnie lub równolegle – zgodnie z konfiguracją w danym etapie. Dokładny opis działania AWS CodePipeline znajduje się w runbook’u.
W tym wpisie pokażemy:
- Jak stworzyć pipeline ciągłości dostarczania oprogramowania z pomocą AWS CodePipeline, zapewniany przez AWS CloudFormation.
- Jak skonfigurować pipeline działania i uruchomić go w innym regionie niż został skonfigurowany.
- Jak wdrożyć przykładową aplikację w wielu regionach z pomocą AWS CodeDeploy.

AWS CodeDeploy: zainstaluj i wykorzystaj
AWS CodeDeploy to usługa, która automatyzuje wdrażanie oprogramowania do różnych usług obliczeniowych, takich jak Amazon EC2, AWS Lambda i serwerów on-premise. Aby zainstalować AWS CodeDeploy, należy przygotować instancje Amazon EC2 oraz zainstalować agenta, czyli paczkę software’ową umożliwiającą przeprowadzenie deploymentów. W tym celu można wykorzystać szablony AWS CloudFormation.
Na tym etapie należy:
- utworzyć instancje Amazon EC2 i zainstalować agenta AWS CodeDeploy,
- utworzyć aplikację AWS CodeDeploy.
By usprawnić to działanie można wykorzystać szablon AWS CloudFormation. Zanim rozpocznie się działanie, warto upewnić się, że klucze zostały poprawnie skonfigurowane, tak by umożliwić dostęp SSH do instancji Amazon EC2 w danym regionie.
Amazon S3
Amazon S3 to prosty interfejs usługi internetowej, którego można używać do przechowywania i pobierania dowolnej ilości danych, w dowolnym czasie i z dowolnego miejsca w sieci. Jest to kluczowy komponent dla działania deployment pipeline w AWS CodePipeline.
High-level deployment architecture
Schemat obrazuje (w ogólnym ujęciu) proces wdrożenia architektury na potrzeby procesu deploymentu. Pierwszą fazą jest załadowanie najnowszej wersji kodu aplikacji do usługi Amazon S3. Każda nowa aktualizacja załadowana do bucket’a uruchamia usługę AWS CodePipeline
Dla każdego działania CodePipeline Action w AWS CodeDeploy, kod aplikacji z Amazon S3 jest replikowany do artifact store w regionie dla danego działania. Każde działanie wdraża najnowszą wersję aplikacji do instancji Amazon EC2 w regionie.
Aby stworzyć pipeline w wielu regionach, należy wykonać następujące kroki:
- Skonfigurować zasoby, które będą potrzebne przy wdrożeniu z pomocą AWS CodeDeploy.
- Skonfigurować “artifact stores” (S3 buckets) dla AWS CodePipeline w każdym regionie.
- Utworzyć AWS CloudFormation dla AWS CodePipeline.
- Sprawdzić deploymenty przeprowadzone przez pipeline w AWS Management Console.
- Sprawdzić poprawność zrealizowanych deploymentów.
Co dalej?
Pierwszą czynnością jest zainstalowanie agenta AWS CodeDeploy na instancjach. Agent jest paczką software’ową umożliwiającą przeprowadzenie deploymentów. Na tym etapie należy wykonać 2 czynności:
- utworzyć instancje Amazon EC2 i zainstalować agenta AWS CodeDeploy,
- utworzyć aplikacje AWS CodeDeploy.
By usprawnić to działanie można wykorzystać szablon AWS CloudFormation.
UWAGA! Zanim rozpoczniemy działanie, warto upewnić się, że klucze zostały poprawnie skonfigurowane, tak by umożliwić dostęp SSH do instancji Amazon EC2 w danym regionie. Dokładna instrukcja jak to zrobić znajduje się tutaj.
Etap 1
By uruchomić instancje Amazon EC2 i AWS CodeDeploy można skorzystać z przygotowanych przez AWS szablonów AWS CloudFormation (dostępne w linkach poniżej):
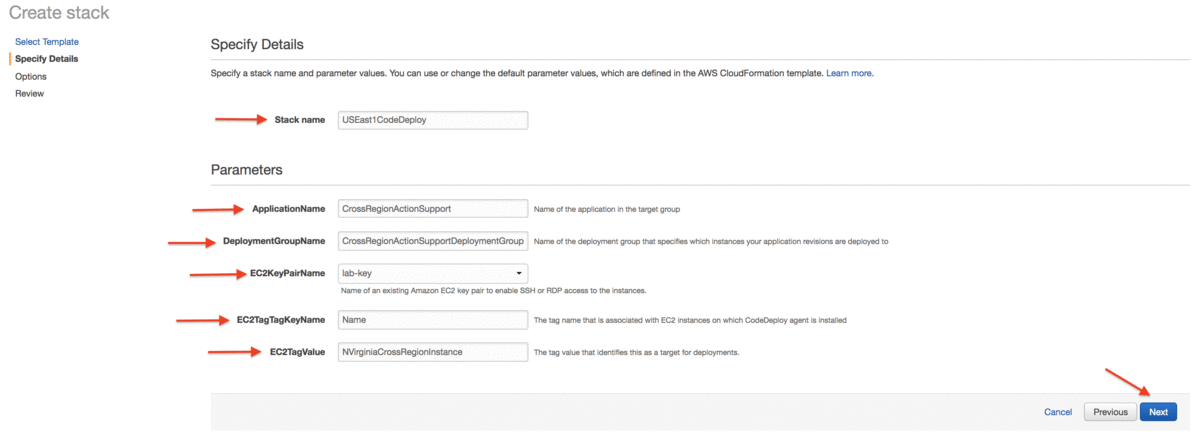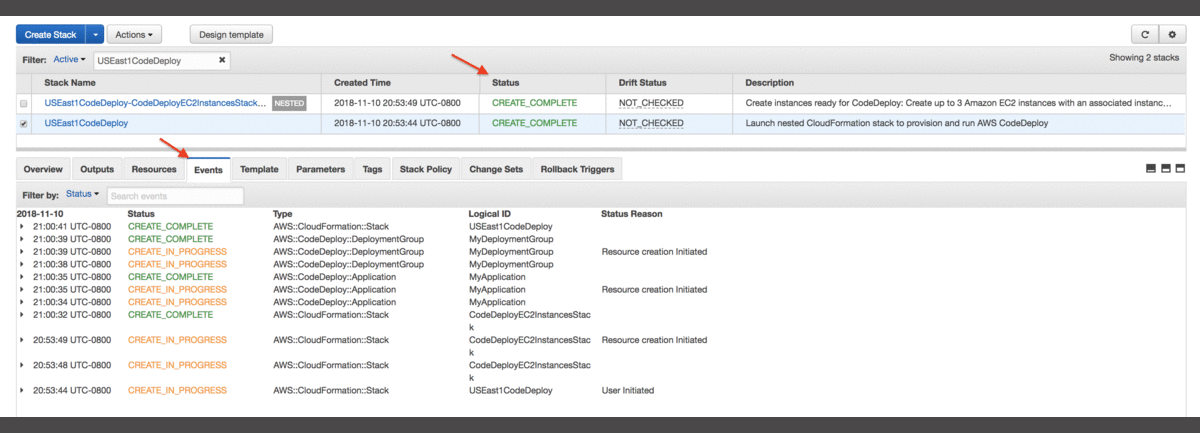
W konsoli AWS, na stronie Specify details należy wykonać następujące czynności:
- W Stack Name wprowadzić nazwę dla stack’a (np. USEast1CodeDeploy).
- W ApplicationName wprowadzić nazwę aplikacji (np. CrossRegionActionSupport).
- W polu DeploymentGroupName wprowadzić nazwę grupy wdrażania (np. CrossRegionActionSupportDeploymentGroup).
- W EC2KeyPairName – jeśli mamy już parę kluczy do użycia z instancjami Amazon EC2 w tym regionie, wybieramy istniejącą parę kluczy, a następnie wybieramy swoją parę kluczy.
- W polu EC2TagKeyName wpisujemy nazwę.
- W EC2TagValue wpisujemy NVirginiaCrossRegionInstance.
- W konsoli wybieramy Next.
Tworzenie zasobów może zająć kilka minut. Progres można obserwować w konsoli w zakładce Events. Gdy stack zostanie stworzony, w kolumnie Status pojawi się komunikat “CREATE_COMPLETE”.
Nowo powstałe instancje powinny być widoczne w każdym z regionów, w którym realizowany był deployment.
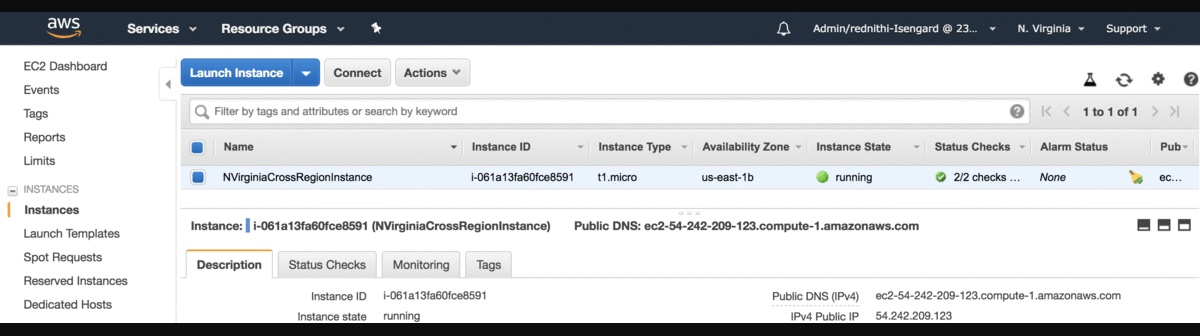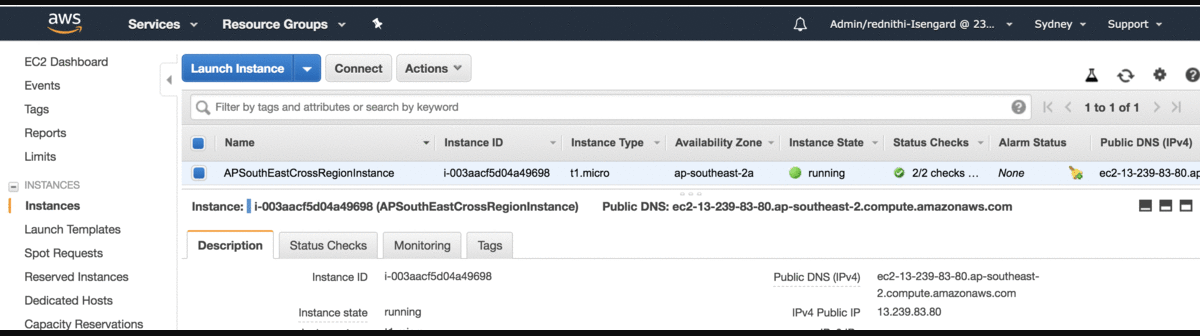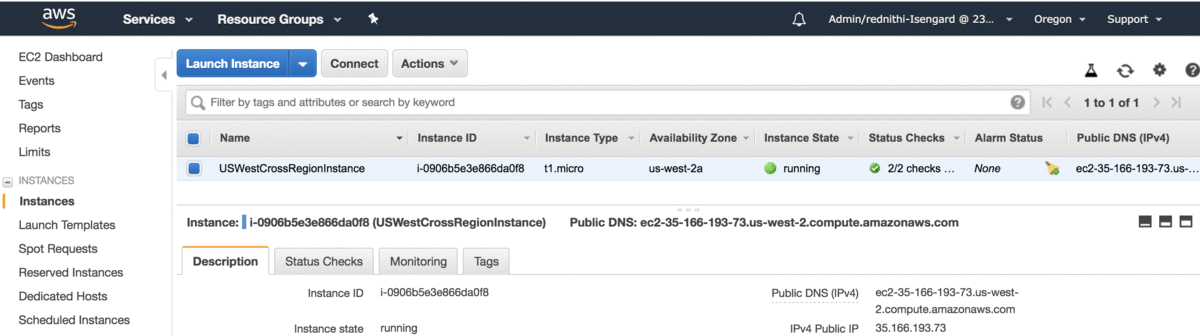
Etap 2
Należy skonfigurować store’y artefaktów dla AWS CodePipeline. Amazon S3 wykorzystuje buckety jako magazyny artefaktów. Buckety są regionalne i wersjonowane. Wszystkie artefakty są kopiowane do regionu, w którym działanie związane pipeline’em ma zostać wykonane.
By utworzyć takie magazyny za pomocą AWS CloudFormation należy pobrać szablon dla każdego z regionów.
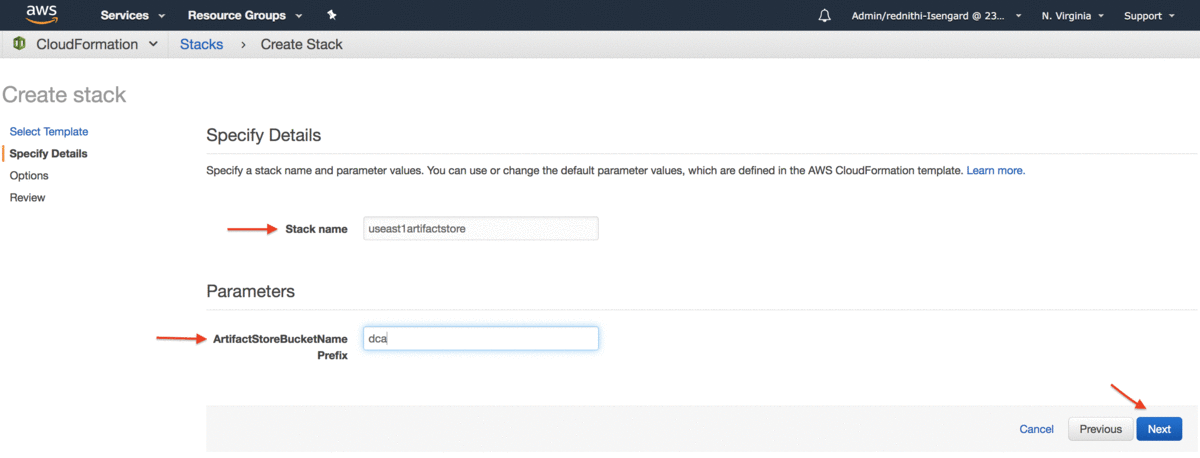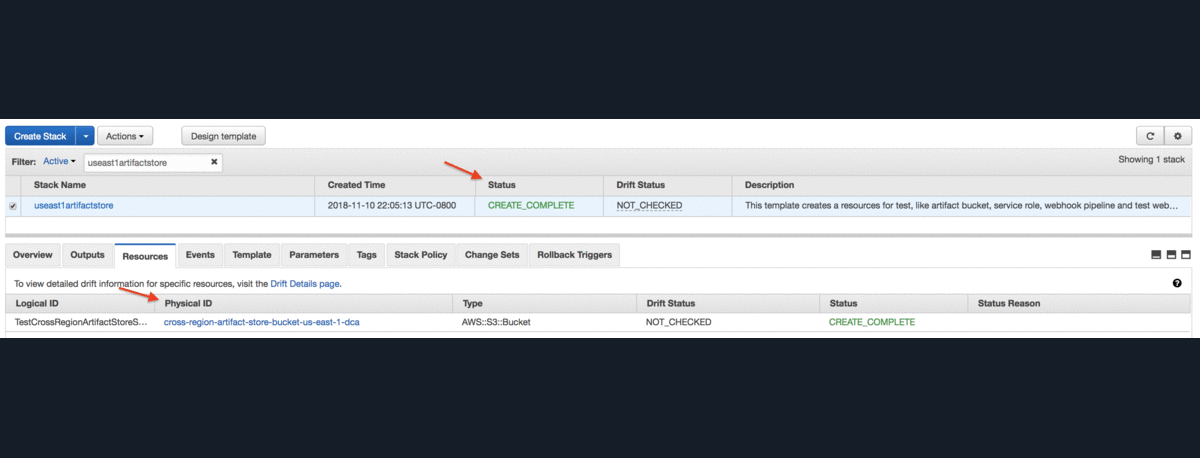
W konsoli na stronie Specify details należy wykonać następujące czynności:
- W Stack name , wprowadzić nazwę dla stosu (na przykład artifactstore).
- W ArtifactStoreBucketNamePrefix wprowadzić ciąg prefiksu o długości do 30 znaków. Użyć tylko małych liter, cyfr, kropek i łączników (na przykład useast1).
- Wybrać Next.
Podobnie jak wcześniej, tworzenie zasobów może potrwać kilka minut, a postęp działania widoczny jest w zakładce Events w konsoli AWS.
Trzeba pamiętać o skopiowaniu nazw bucketów Amazon S3 ze wszystkich regionów. Będą potrzebne w następnych krokach.
WAŻNE! Wszystkie buckety, w tym bucket dla Source action w pipelinie, muszą mieć możliwość śledzenia wersji uploadowanych i procesowanych przez AWS CodePipeline.
Etap 3
Należy użyć szablonu AWS CloudFormation do zdefiniowania zasobów:
- Amazon S3 Bucket (source bucket na kod źródłowy aplikacji)
- AWS CodePipeline, dla którego należy zdefiniować odpowiednie akcje w ramach faz pipeline-a: Source action (S3) i odpowiednią liczbę Deploy action (typu CodeDeploy) dla każdego regionu.
By stworzyć nowy bucket S3 należy uruchomić konsolę, a następnie wybrać usługę AWS CloudFormation, pobrać templatkę i uruchomić ją w głównym regionie.
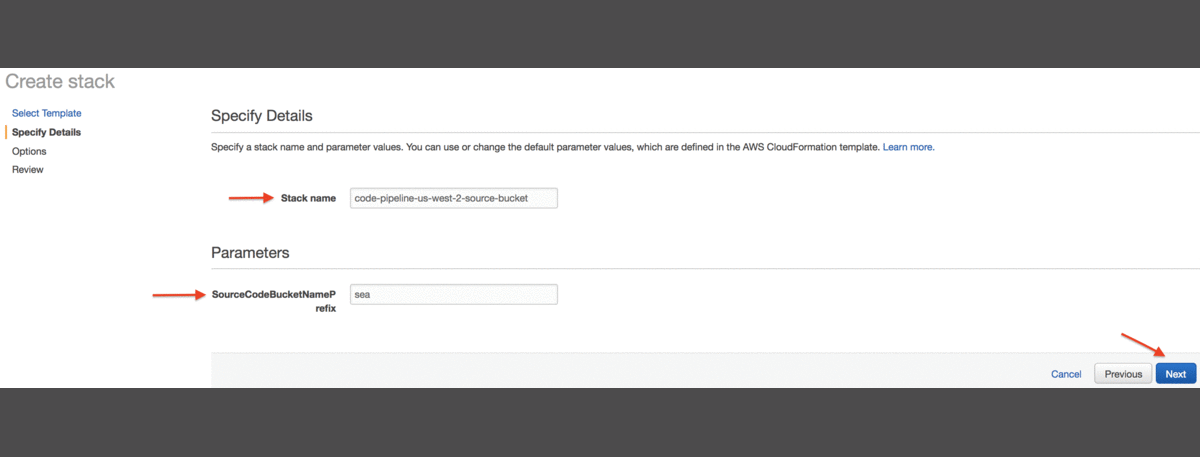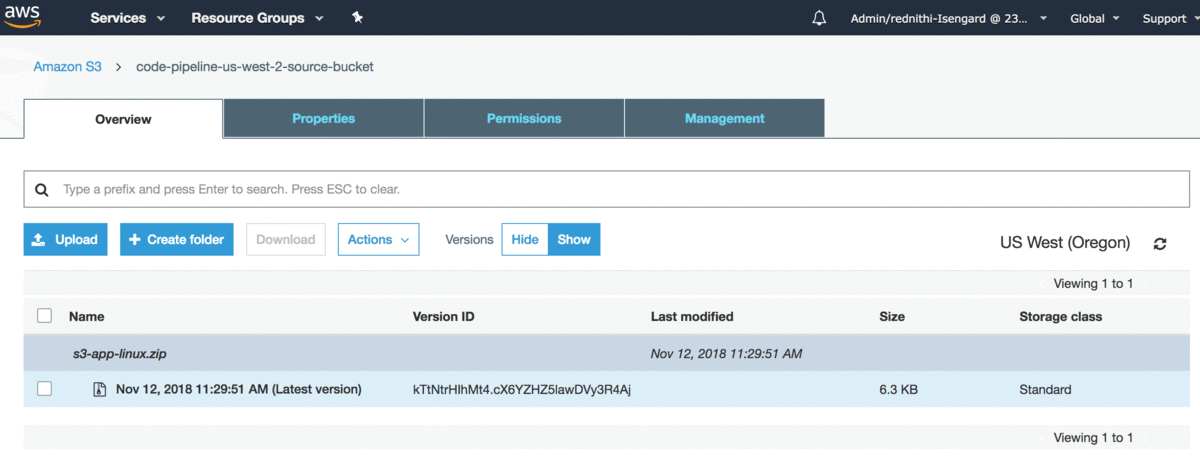
Na stronie Specify details należy wykonać następujące czynności:
- W Stack name , wprowadzić nazwę dla stacku (na przykład code-pipeline-us-west2-source-bucket). Powinna zawierać nazwę regionu.
- W SourceCodeBucketNamePrefix wprowadzić ciąg prefiksu o długości do 30 znaków. Należy używać tylko małych liter, cyfr, kropek i łączników (na przykład uswest2).
- Wybrać Next w konsoli.
Tworzenie zasobów może potrwać kilka minut, a progres jest widoczny w zakładce Events w konsoli AWS.
Gdy proces tworzenia zostanie zakończony, należy pobrać przykładową aplikację z s3-app-linux.zip i załadować ją do bucket’a kodu źródłowego.
By stworzyć nowy pipeline w AWS CodePipeline, należy:
W konsoli uruchomić pobrany szablon AWS CloudFormation w głównym regionie, us-west-2.
By utworzyć Stack, należy wykonać następujące kroki:
- W Stack name , wprowadzić nazwę dla stacka (np CrossRegionCodePipeline).
- W ApplicationName wprowadzić nazwę aplikacji (na przykład CrossRegionActionSupport).
- W APSouthEast2ArtifactStoreBucket wpisać cross-region-artifact-store-bucket-ap-southeast-2 lub wprowadzić nazwę podaną w kroku 2 dla bucketa Amazon S3 utworzonego w ap-southeast-2.
- W polu DeploymentGroupName wprowadzić nazwę deployowanej grupy (na przykład CrossRegionActionSupportDeploymentGroup).
- W S3SourceBucketName wprowadzić code-pipeline-us-west-2-source-bucket lub wprowadzić nazwę podaną w kroku 3.
- W USEast1ArtifactStoreBucket wpisać cross-region-artefact-store-bucket-us-east-1 lub wprowadzić nazwę podaną w kroku 2 dla bucketa Amazon S3 utworzonego w us-east-1.
- W USWest2ArtifactStoreBucket wpisać cross-region-artefact -store-bucket-us-west-2 lub wprowadzić nazwę podaną w kroku 2 dla bucketa Amazon S3 utworzonego w us-west-2.
- W S3SourceBucketKey wprowadzić pobraną apkę s3-app-linux.zip.
- W konsoli wybierać Next.
Etap 4
Teraz możemy sprawdzić w konsoli AWS deploymenty przeprowadzone przez przygotowany pipelinie. W konsoli S3 należy przejść do bucketa źródłowego i skopiować ID wersji.
Następnie przejść do AWS CodePipeline i przejść do pipeline’u, który właśnie został stworzony. Należy zauważyć, że ID wersji jest takie samo we wszystkich regionach, zarówno w source action jak i wszystkich deploy actions. Deployment został zakończony z sukcesem.
By upewnić się co do pomyślności działań, w przeglądarce wpisujemy publiczny adres IP instancji Amazon EC2, który był zapewniony przez AWS CodeDeploy w etapie 1. W przeglądarce powinien ukazać się komunikat jak poniżej.
Podsumowanie
Podsumowując, właśnie wykonaliśmy deployment multiregionowy, bez konieczności martwienia się o proces kopiowania kodu pomiędzy regionami. By wprowadzić kolejne zmiany, wystarczy zaaplikować zmiany w kodzie źródłowym w głównym regionie, a zostaną one wdrożone automatycznie za pomocą AWS CodeDeploy. Zmiany w kodzie można również wykorzystać do budowania i testowania pomiędzy regionami. Gdy znamy już możliwości deploymentu, kolejnym krokiem jest usunięcie bucketów i stacka. Pomimo, że buckety zostały stworzone za pomocą AWS CloudFormation, nie ma możliwości by je usunąć wraz ze stackiem. W tym celu należy wejść do konsoli Amazon S3 i wykonać kroki umieszczone w instrukcji usuwania/opróżniania bucketów. By usunąć stack AWS CloudFormation, należy postępować zgodnie z krokami w instrukcji.
Jeśli pojawią się dodatkowe pytania, zawsze warto skorzystać z forum AWS CodePipeline lub pomocy AWS Support.
Praktyczne wykorzystanie usług AWS znajdziecie również na naszym kanale na YouTube, gdzie Wojtek Orzechowski opowiada o projekcie, który zrealizowaliśmy dla Goop.com.