How to achieve high availability in AWS cloud computing? We give you a hint!
In today’s world, ensuring high availability (HA) of systems has become a critical requirement. However, achieving this goal requires implementing advanced mechanisms that eliminate single points of failure. Cloud platforms such as AWS offer a range of tools and design patterns that enable the building of highly available applications, making them a natural choice for full HA. Let’s take a closer look at some of the mechanisms that provide High Availability in Amazon Web Services.
Auto Scaling and Load Balancing
In a cloud environment where application load can fluctuate from second to second, auto scaling and load balancing form the foundation of high availability and system performance. A widely used solution available in AWS is Elastic Load Balancer (ELB), which automatically distributes incoming traffic (e.g., HTTP, HTTPS, TCP) across multiple Amazon EC2 instances, containers, or IP addresses in one or multiple Availability Zones. AWS ELB comes in three types – Application Load Balancer, Network Load Balancer, and Gateway Load Balancer.
Key advantages of Elastic Load Balancer include automatic detection of unhealthy instances (thanks to health checks), automatic removal of unavailable instances from the pool, multi-AZ traffic handling, and fast reaction to scaling. Closely related to ELB is the Auto Scaling Group, within which we can dynamically create similar, stateless Amazon EC2 instances. By scaling horizontally (that is: adding more small instances instead of building one large one), we minimize costs and eliminate a single point of failure.
Moreover, the number of instances in an Auto Scaling Group can be adjusted automatically in response to changing traffic and resource demand (e.g., based on CPU or RAM usage metrics). During peak hours, additional instances can automatically spin up to maintain service continuity, while during off-peak hours, unused instances can terminate themselves to reduce costs. This dynamic, stateless approach to Amazon EC2 also facilitates quick failure recovery by replacing a faulty instance.
Leveraging multiple Availability Zones
One of the greatest advantages of using AWS is the ability to build systems resilient to physical infrastructure failures such as data center outages, network failures, or power loss. Every AWS Region consists of at least two Availability Zones. Each Availability Zone is a separate data center or a group of data centers with independent power, cooling, and networking infrastructure. Even though these locations are physically separated, they are connected by a fast, redundant, low-latency network.
When configuring Auto Scaling Groups or Elastic Load Balancers, we can leverage multiple Availability Zones. Importantly, other services can also span multiple Availability Zones, such as Amazon RDS databases, Amazon S3 buckets, or AWS Lambda functions. This eliminates another potential source of failure, thus increasing availability and resilience.
High Availability of data resources in AWS Cloud
A database is a core component of an application, and recovering its data can be extremely challenging. Therefore, applying methods that ensure high availability is crucial to minimizing failure risk. AWS provides a comprehensive set of tools that support replication and backups.
Amazon RDS (Relational Database Service) allows easy configuration of a Multi-AZ database. In this model, the primary database instance runs in one Availability Zone, while AWS automatically creates standby replicas in other zones with real-time data synchronization. In case of failure, AWS automatically redirects traffic to the standby instance, allowing the application to continue operating without major disruptions.
Amazon S3 (Simple Storage Service) is an object storage service designed from the ground up for exceptional data durability. Importantly, data can be stored redundantly across different Availability Zones. Additionally, objects can be versioned, increasing protection against accidental overwrites. By using S3 Cross-Region Replication, we can also replicate data to other AWS Regions, adding another layer of protection.
We should also mention backup creation, for which AWS Backup is an excellent solution. This integrated tool enables the creation and management of backups for multiple AWS services from a single console. With this service, we can easily back up Amazon RDS databases, Amazon DynamoDB tables, or Amazon EC2 instances. AWS services are well-integrated with AWS Backup, simplifying both backup creation and restoration.
Leveraging AWS serverless services
It’s worth highlighting specific high-availability services. Amazon Web Services also offers a wide range of Serverless solutions, where managing servers, infrastructure, or scaling is handled entirely by AWS. We’ve already mentioned one such service – Amazon S3 – but there are many more. Notable examples include AWS Lambda (executing function code in response to events), Amazon API Gateway (managing and publishing APIs), and Amazon DynamoDB (a highly available, scalable NoSQL database).
These services are distributed and redundant across multiple Availability Zones and automatically adjust to varying loads. Importantly – AWS manages the infrastructure, freeing us from maintenance or updates. This greatly increases resilience to failures, overloads, or other unforeseen events, helping to maintain high system availability.
Monitoring and Incident Response: The Key to Maintaining High Availability
Monitoring in AWS is the foundation for maintaining high availability. A key service here is Amazon CloudWatch, which provides real-time detailed metrics covering CPU usage, memory, network traffic, and latency. With Amazon CloudWatch, we can monitor infrastructure (e.g., Amazon EC2 instances or Amazon RDS) as well as applications (e.g., AWS Lambda or Amazon API Gateway). Meanwhile, CloudWatch Logs allows log analysis, essential for diagnosing application errors.
But that’s not all! Amazon CloudWatch can also trigger predefined actions based on thresholds, ranging from sending alerts via Amazon SNS (Amazon Simple Notification Service) to running advanced AWS Lambda functions for remediation.
AWS also offers other services that support high availability. Implementing AWS Config enables monitoring configuration compliance with best practices, reducing failure risk. AWS Trusted Advisor helps proactively identify potential issues before they escalate into serious incidents. We should also mention Amazon GuardDuty, a monitoring complement that uses ML and AI to detect unusual activities in the infrastructure, such as suspicious logins, data exfiltration, or port scanning. Finally, AWS Health Dashboard provides personalized information on the status of AWS services affecting your resources, showing current outages, scheduled maintenance, and recommendations for improving availability.
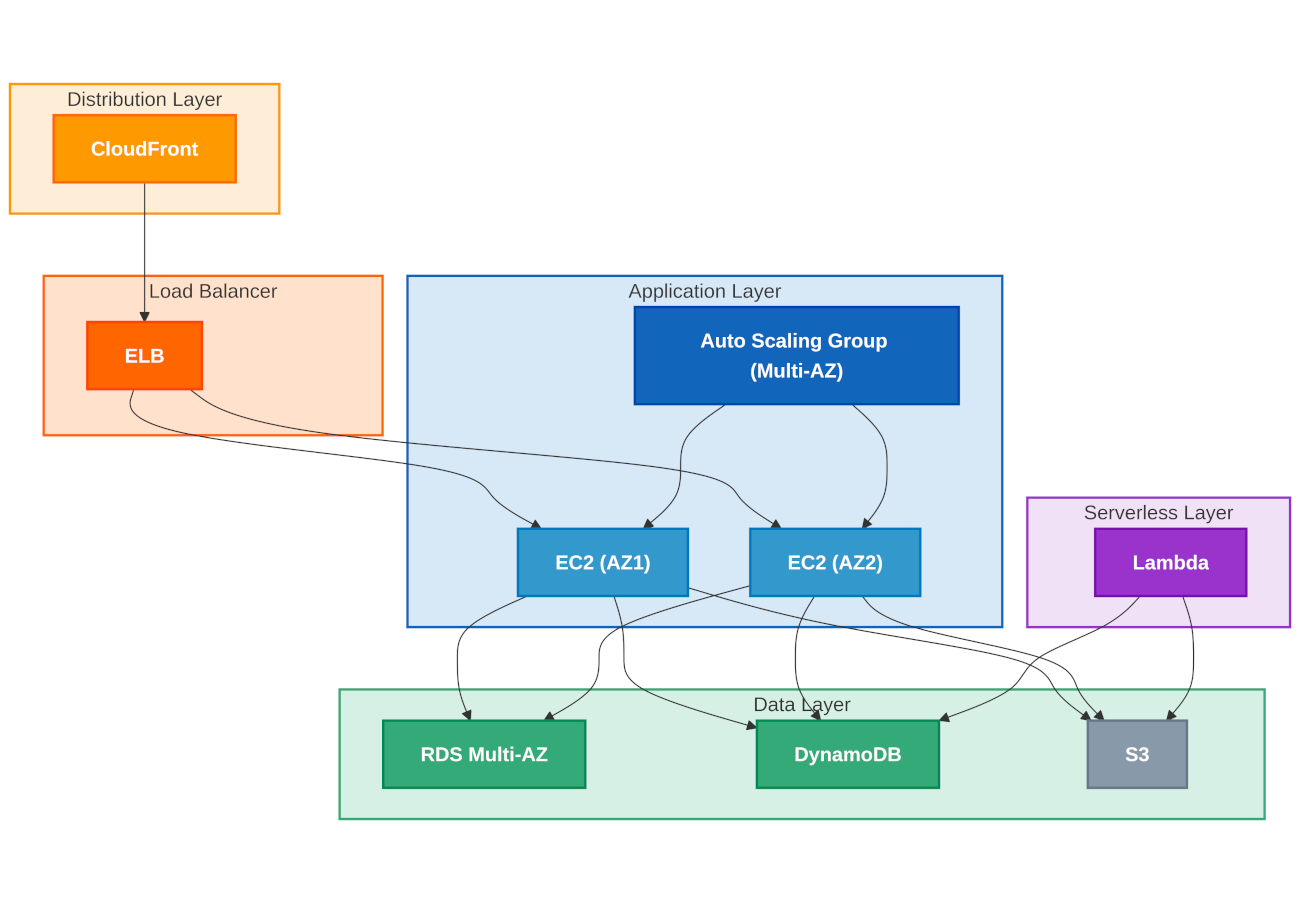
Example of a High Availability architecture in AWS Cloud
When designing a high-availability infrastructure in Amazon Web Services, it’s worth leveraging proven architectural patterns. A solid HA architecture should consist of a multi-tier web application using Amazon CloudFront for edge content distribution and Elastic Load Balancer for traffic balancing, directing requests to Amazon EC2 instances grouped in Auto Scaling Groups across at least two Availability Zones. This approach effectively eliminates single points of failure at the application layer.
The data layer in a high-availability architecture must also be redundant. Amazon RDS databases configured with Multi-AZ and automatic failover, Amazon DynamoDB with built-in multi-AZ replication, and Amazon S3 for static content and backups create a robust foundation for data storage and processing. Serverless services such as AWS Lambda further increase system resilience through automatic scaling and distribution across Availability Zones.
The entire infrastructure should be covered by comprehensive monitoring and automated remediation. Amazon CloudWatch with alarms and AWS Config for configuration compliance monitoring enable rapid problem detection and response. Amazon Simple Notification Service ensures effective incident alerts, while AWS Backup enables regular backups of critical resources, forming the final line of defense in a high-availability strategy.
Summary
In this article, we’ve covered several AWS cloud solutions that enable achieving high service availability. Achieving High Availability in AWS is possible thanks to the use of multiple Availability Zones, auto scaling, and load balancing. Let’s not forget about redundant database solutions (Amazon RDS Multi-AZ, Amazon DynamoDB) and an appropriate set of monitoring and incident response tools (Amazon CloudWatch). Designing cloud infrastructure in line with best practices enables a high level of availability alongside the implementation of modern solutions that facilitate growth and scaling.
Would you like to achieve high availability in AWS Cloud? Contact our cloud infrastructure architects for expert assistance in designing a solution aligned with High Availability conventions! Write to our experts at kontakt@lcloud.pl.