Amazon Neptune - visual dimension of the database
There are many types of databases, and the most common are relational databases. They are based on “relations” between data, which are presented in the form of tables. Amazon Neptune is a service that uses graph structures with nodes, access points and properties to present and store data in the form of graphs. It finds its place in applications such as e-commerce recommendation engines, fraud detection, building knowledge charts or during network security analysis. The operation of the service is presented in the chart below.
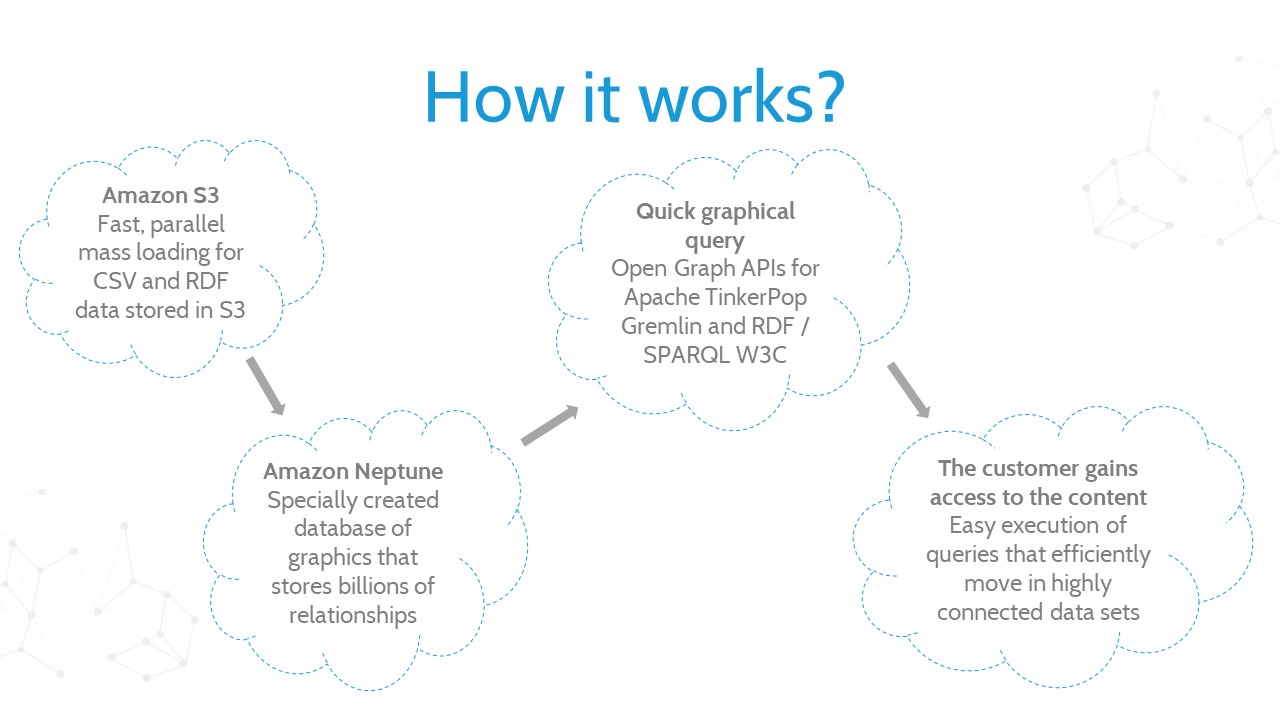
The main advantages of Amazon Neptune:
- Supports for Open Graph APIs – support tools such as Gremlin or SPARQL, while allowing the selection of the chart model, properties and language of open source queries, while ensuring high efficiency of their operation.
- Is highly efficient and scaled – works on the basis of a specially designed, powerful database engine, optimized for storing billions of relationships and checking latency in milliseconds.
- Is highly available and durable – has the function of automatic healing and damage-resistant mass storage created for the cloud, which creates up to six copies of data in three different accessibility zones (Availability Zones). In addition, it constantly backs up data to the Amazon S3 service and transparently recovers lost data during a disaster.
- Is on a high level of security – allows for multi-level data protection and access to them thanks to network isolation thanks to the use of a virtual private network (VPC) and the possibility of encrypting data in rest (using the AWS KMS service).
How much does it cost to use the solution?
Amazon Neptune is a service billed in the pay-per-use model, i.e. payments only for the resources used. This allows you to free yourself from the unnecessary start-up costs and complexity of planning the purchase of database capacity in advance.
Service costs include both the cost of the main database instances used for reading and writing the tasks and the Amazon Neptune replicas that are used to scale readings and failover. Amazon Neptune uses the architecture of multiple access zones (Multi-AZ) during emergency switching to a replica in the event of a failure. The cost of implementing this configuration is the cost of the basic instance and the cost of the Amazon Neptune replica instance.
Detailed calculations for each of the regions can be found in the Pricing tab.
Here are some examples where databases presented with graphs can perform much better than relational or NoSQL databases.
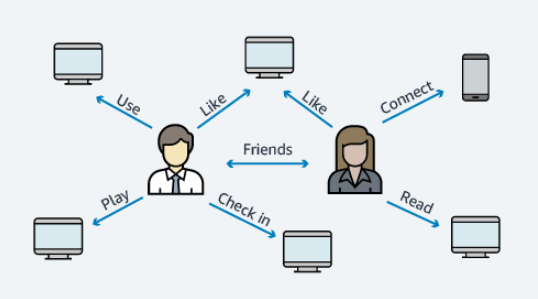
Social Networking
Thanks to Amazon Neptune you can quickly and easily process large interactions sets to create social applications. Thanks to its functionality, allows prioritizing the order of updates displayed to the user.
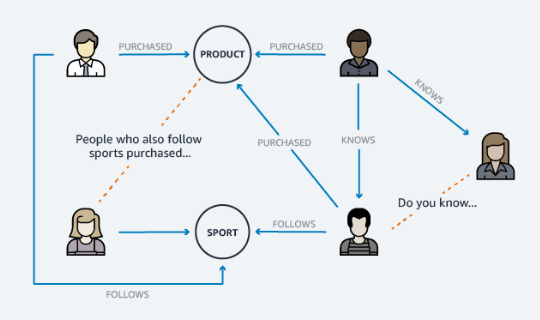
Recommendation Engines
Amazon Neptune allows you to use the highly available database more efficiently to create product recommendations. Recommendations are based on a comparison of similar shopping histories among users or mutual friends.
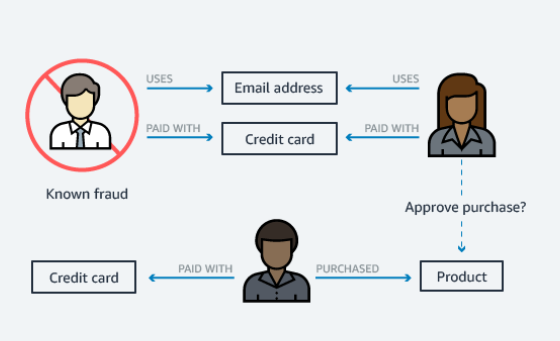
Fraud Detection
Functionality particularly important for the financial and service industry. It allows you to monitor transactions in near real time. By creating graphical queries, in order to quickly detect patterns of relationships, the effectiveness of fraud detection increases.
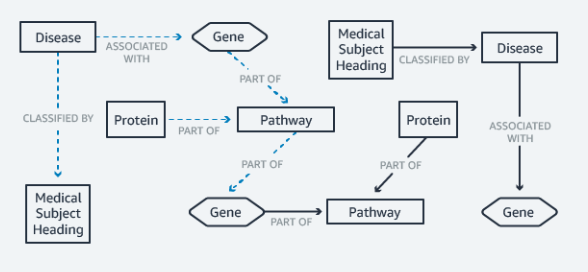
Knowledge Graphs
Education is another area where you can apply this database model. Using knowledge charts, you can easily update information or expand and check complex regulatory rules models. An example is the Wikidata portal.
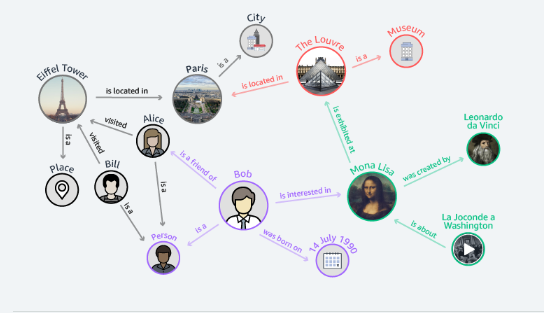
Life Sciences
With Amazone Neptune, you can also store data such as disease models and genetic patterns. With its help, you can easily model relationships and chemical reactions that can be used in scientific publications.
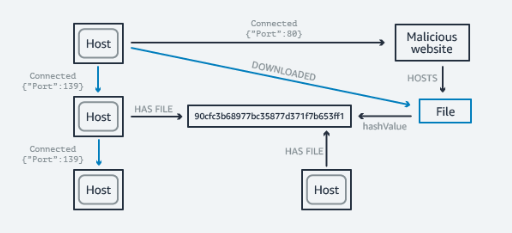
Network / IT operations
Amazon Neptune gives you the ability to store and process events to manage and secure your network. Using the service, you can easily understand how anomaly can affect the network (creating a query for a chart pattern using event attributes).
All the above models show the improvements introduced by the Amazon Neptune service, which saves time when performing tasks such as configuration and maintenance, updating, backup, data recovery, failure detection and repair.
Amazon Neptune has been designed to help provide the user with a high level of SLA, further enhancing database performance by tightly integrating the database engine with a virtual storage layer, based on SSD drives, built to work with databases. Thanks to such a wide range of applications, ease of use and favourable price conditions, the implementation of Amazon Neptune is extremely easy, and in the long-term – cost-effective.