Amazon Neptune - wizualny wymiar bazy danych
Istnieje wiele rodzajów baz danych, a najpowszechniejsze to bazy relacyjne. Oparte są na “relacjach” pomiędzy danymi, które prezentowane są w formie tabel. Amazon Neptune to usługa wykorzystująca struktury grafów z węzłami, punktami dostępu i własnościami do przedstawiania i przechowywania danych w formie grafów. Znajduje swoje miejsce w zastosowaniach takich jak: silniki rekomendacji dla e-commerce, wykrywanie oszustw, budowanie wykresów wiedzy czy podczas analizy bezpieczeństwa sieci. Działanie usługi zostało przedstawione na poniższym wykresie.
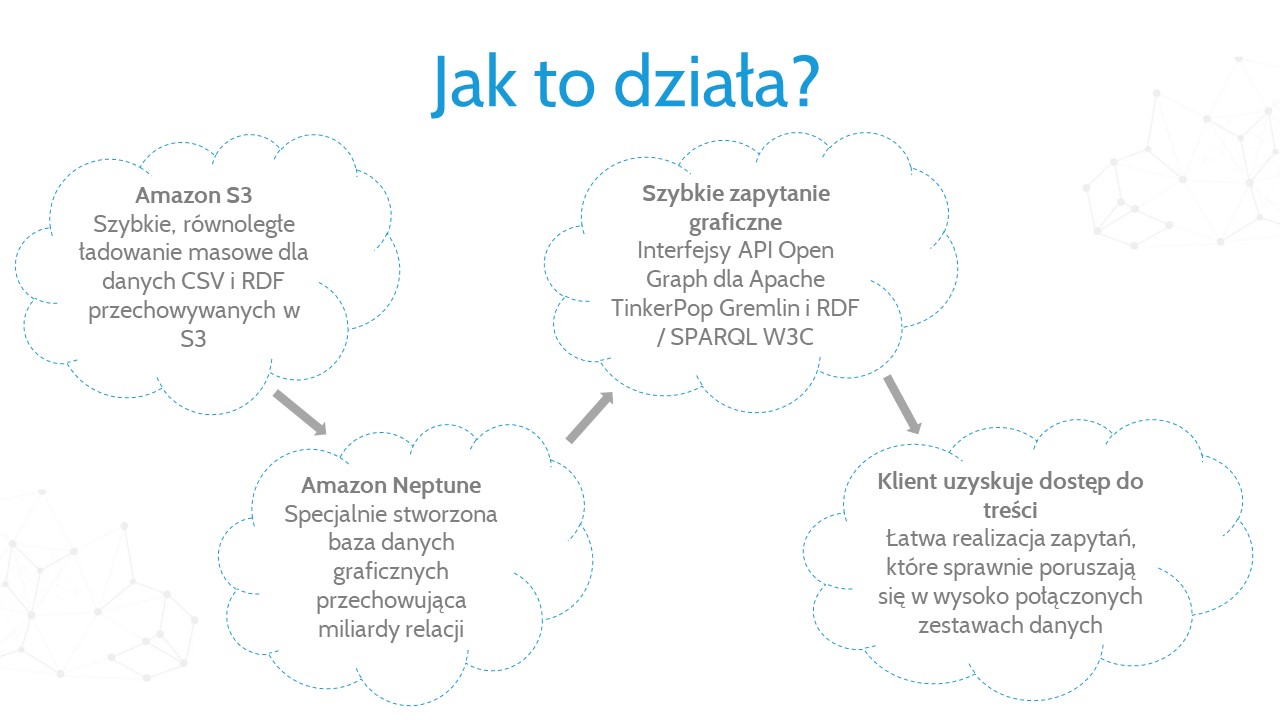
Główne zalety Amazon Neptune:
- Obsługa interfejsów API Open Graph – wspiera takie narzędzia jak Gremlin czy SPARQL, jednocześnie umożliwiając wybór modelu wykresu, właściwości i języka zapytań open source, przy tym zapewniając wysoką wydajność ich działania.
- Jest wysoce wydajna i skalowana – działa w oparciu o specjalnie zaprojektowany, wydajny silnik bazy danych, zoptymalizowany do przechowywania miliardów relacji i sprawdzania opóźnień w milisekundach.
- Jest wysoce dostępna i wytrzymała – posiada funkcję automatycznego uzdrawiania (autohealingu) i odporną na uszkodzenia pamięć masową stworzoną dla chmury, która tworzy aż sześć kopii danych, w trzech różnych strefach dostępności (Availability Zones). Dodatkowo stale tworzy kopie zapasowe danych w usłudze Amazon S3 oraz transparentnie odzyskuje dane, utracone podczas awarii.
- Jest bardzo bezpieczna – pozwala na wielopoziomowe zabezpieczenie danych i dostępu do nich dzięki izolacji sieciowej, i wykorzystaniu wirtualnej sieci prywatnej (VPC) oraz możliwości szyfrowania danych w spoczynku (in rest) z użyciem usługi AWS KMS.
Ile kosztuje korzystanie z rozwiązania?
Amazon Neptune jest usługą rozliczaną w modelu pay-per-use, czyli płatności tylko za wykorzystywane zasoby. Umożliwia to uwolnienie się od niepotrzebnych kosztów początkowych i złożoności planowania zakupu pojemności bazy danych z wyprzedzeniem.
Na koszty usługi składa się zarówno koszt głównych instancji bazodanowych, używanych do zadań odczytu i zapisu, jak i replik Amazon Neptune, które używane są do skalowania odczytów i przełączania awaryjnego. Amazon Neptune wykorzystuje architekturę wielu stref dostępności (Multi-AZ) podczas awaryjnego przełączania do repliki w przypadku awarii. Koszt implementacji takiej konfiguracji to koszt instancji podstawowej oraz koszt instancji repliki Amazon Neptune.
Szczegółowe wyliczenia dla każdego z regionów znajdują się w zakładce Pricing.
Oto kilka przykładów, gdzie bazy danych przedstawione za pomocą grafów mogą sprawdzić się o wiele lepiej niż bazy relacyjne czy NoSQL.
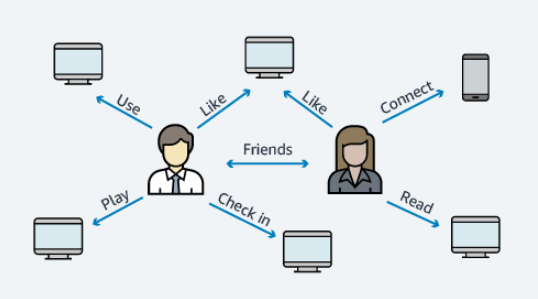
Sieci społecznościowe
Dzięki Amazon Neptune można w szybki i łatwy sposób przetwarzać duże zestawy interakcji, w celu tworzenia aplikacji społecznościowych. Dzięki swojej funkcjonalności, pozwala priorytetyzować kolejność aktualizacji wyświetlanych użytkownikowi.
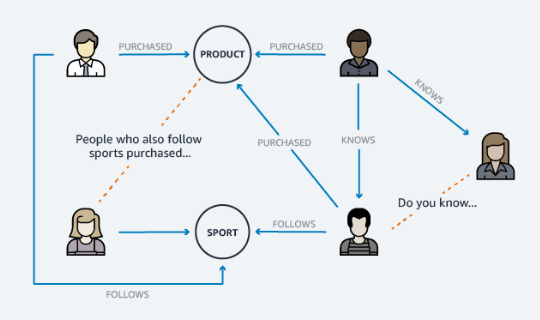
Silniki rekomendacji
Amazon Neptune pozwala na bardziej efektywne korzystanie z wysoce dostępnej bazy danych, w celu tworzenia rekomendacji produktów. Rekomendacje oparte są na porównaniu podobnych historii zakupów wśród użytkowników lub wspólnych znajomych.
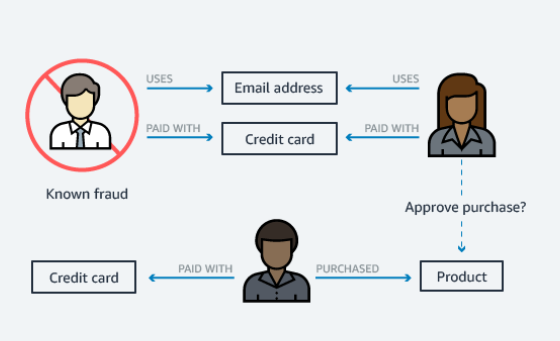
Wykrywanie oszustw
Funkcjonalność szczególnie istotna dla branży finansowo-usługowej. Pozwala na monitorowanie transakcji w czasie zbliżonym do rzeczywistego. Dzięki tworzeniu zapytań graficznych, w celu szybkiego wykrywania wzorców relacji, zwiększa się skuteczność wykrycia oszustwa.
Wykresy wiedzy
Edukacja to kolejny obszar, w którym można zastosować ten model bazy danych. Za pomocą wykresów wiedzy z łatwością można aktualizować informacje czy rozbudowywać i sprawdzać złożone modele reguł regulacyjnych. Przykładem może być portal Wikidata.
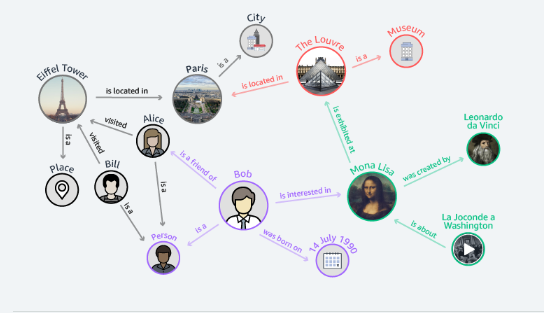
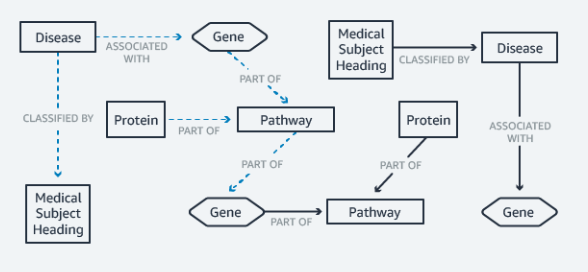
Nauki przyrodnicze
Przy pomocy Amazon Neptune można również przechowywać takie dane jak modele chorób czy wzorce genetyczne. Z jej pomocą można z łatwością modelować związki i reakcje chemiczne, które mogą zostać wykorzystane w publikacjach naukowych.
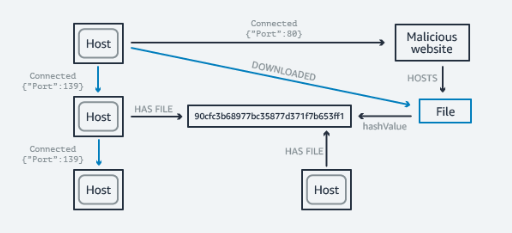
Operacje sieciowe/IT
Neptune daje możliwość przechowywania i przetwarzania zdarzeń w celu zarządzania i zabezpieczania sieci. Za pomocą usługi można w prosty sposób zrozumieć jak anomalia może wpływać na sieć (tworząc zapytanie o wzorzec wykresu za pomocą atrybutów zdarzenia).
Wszystkie powyższe modele pokazują usprawnienia, jakie wprowadza usługa Amazon Neptune, która pozwala na oszczędność czasu podczas wykonywania takich zadań jak: konfigurowanie i utrzymywanie, aktualizowanie, tworzenie kopii zapasowych, odzyskiwanie danych, wykrywanie awarii oraz ich naprawy.
Amazon Neptune został zaprojektowany tak, aby pomóc zapewnić użytkownikowi wysoki poziom wskaźnika SLA , dodatkowo zwiększając wydajność bazy danych poprzez ścisłą integrację silnika bazy danych z wirtualną warstwą pamięci masowej, opartej na dyskach SSD, zbudowanej do pracy z bazami danych. Dzięki tak szerokiemu spektrum zastosowań, prostocie obsługi oraz korzystnym warunkom cenowym, wdrożenie Amazon Neptune jest niezwykle łatwe, a w dłuższej perspektywie czasowej – opłacalne.