Jak uzyskać wysoką dostępność w chmurze obliczeniowej AWS? Podpowiadamy!
W dzisiejszym świecie zapewnienie wysokiej dostępności systemów (High Availability) stało się kluczowym wymogiem. Jednakże osiągnięcie tego wymaga wdrożenia zaawansowanych mechanizmów eliminujących pojedyncze punkty awarii. Platformy chmurowe takie jak AWS oferują szereg narzędzi i wzorców projektowych umożliwiających budowanie wysoce dostępnych aplikacji, dlatego warto z nich skorzystać jako ze sposobu na pełne HA. Przyjrzymy się więc niektórym z mechanizmów zapewniających High Availability w Amazon Web Services.
Automatyczne skalowanie i równoważenie obciążenia
W środowisku chmurowym, gdzie obciążenie aplikacji może zmieniać się z sekundy na sekundę, automatyczne skalowanie i równoważenie obciążenia (Load Balancing) stanowią podstawę wysokiej dostępności i wydajności systemu. Często wykorzystywanym rozwiązaniem dostępnym w AWS jest Elastic Load Balancer (ELB), który automatycznie rozkłada ruch przychodzący (np. HTTP, HTTPS, TCP) pomiędzy wiele instancji Amazon EC2, kontenerów lub adresów IP w jednej lub wielu strefach dostępności (Availability Zones). AWS ELB dzieli się na trzy typy – Application Load Balancer, Network Load Balancer oraz Gateway Load Balancer.
Ogromnymi zaletami Elastic Load Balancer są: automatyczne wykrywanie niedziałających instancji (dzięki systemowi health checks), samoczynne usuwanie niedostępnych instancji z puli, obsługa ruchu w wielu strefach dostępności oraz szybka reakcja na skalowanie. Usługą ściśle powiązaną z ELB jest Automatic Scaling Group, w ramach której możemy dynamicznie tworzyć podobne do siebie, bezstanowe instancje Amazon EC2. Skalując horyzontalnie (to znaczy: dodając kolejne, małe instancje, zamiast tworzyć jedną, wielką), minimalizujemy koszty oraz pozbywamy się pojedynczego punktu awarii (single point of failure).
Co więcej, zmiana liczby instancji w Automatic Scaling Group może być dokonywana automatycznie, w reakcji na zmieniający się ruch i zapotrzebowanie na zasoby (np. w oparciu o metryki użycia CPU czy pamięci RAM), dzięki czemu, w godzinach szczytu, mogą samoczynnie wystartować kolejne instancje zapewniając ciągłość pracy usług, a kiedy ruch opadnie, instancje te mogą same się usunąć minimalizując koszty. Takie dynamiczne i bezstanowe podejście do Amazon EC2 pozwala również na prostą i szybką naprawę awarii poprzez wymianę uszkodzonej instancji.
Wykorzystywanie wielu stref dostępności
Jedną z największych zalet korzystania z AWS jest możliwość budowania systemów odpornych na awarie fizycznej infrastruktury, takich jak awaria centrum danych, sieci czy zasilania. Każdy region AWS składa się z co najmniej dwóch stref dostępności. Każda strefa dostępności to oddzielne centrum danych lub grupa centrów z niezależną infrastrukturą zasilania, chłodzenia i sieci. Mimo tego, że te lokalizacje są od siebie fizycznie odseparowane, to są połączone szybką i redundantną siecią o bardzo niskim opóźnieniu.
Tworząc Automatic Scaling Groups czy Elastic Load Balancers możemy wykorzystywać wiele stref Availability Zones. Co ważne, inne usługi również mogą istnieć w wielu strefach dostępności. Mowa tu chociażby o bazach danych Amazon RDS, bucketach Amazon S3 czy funkcjach AWS Lambda. To sprawia, że eliminujemy kolejny element mogący być źródłem awarii, tym samym zwiększając dostępność i odporność.
Wysoka dostępność zasobów danych w chmurze AWS
Baza danych to główny komponent aplikacji, a odtworzenie danych znajdujących się w niej może być niezwykle trudne. Dlatego tak bardzo ważnym jest stosowanie metod zachowania wysokiej dostępności, co znacznie minimalizuje ryzyko awarii. W AWS mamy do dyspozycji cały zestaw narzędzi, które wspierają replikację i tworzenie backupów.
Amazon RDS (Relational Database Service) umożliwia bardzo łatwą konfigurację bazy danych w trybie Multi-AZ. W tym modelu główna instancja bazy działa w jednej strefie dostępności, a AWS automatycznie tworzy zapasowe instancje (repliki) w innych strefach, gdzie dane są synchronizowane w czasie rzeczywistym. W razie awarii AWS automatycznie przełączy ruch do zapasowej instancji, dzięki czemu aplikacja może działać dalej bez znaczących zakłóceń.
Amazon S3 (Simple Storage Service) to usługa przechowywania obiektów, która od początku została zaprojektowana z myślą o niezwykle wysokiej trwałości danych. Co ważne, dane mogą być przechowywane redundantnie w różnych strefach dostępności. Ważnym również jest fakt, że obiekty mogą być wersjonowane, co zwiększa odporność na przypadkowe nadpisania danych. Korzystając z funkcji S3 Cross-Region Replication możemy również replikować dane do innych regionów AWS, co daje kolejną warstwę zabezpieczenia.
Nie można też nie wspomnieć o tworzeniu kopii zapasowych, a do tego świetnie nada się usługa AWS Backup. Jest to zintegrowane narzędzie umożliwiające tworzenie i zarządzanie kopiami zapasowymi dla wielu serwisów AWS i to z jednego miejsca. Dzięki tej usłudze w prosty sposób wykonamy backup, między innymi, systemów bazodanowych Amazon RDS, Amazon DynamoDB czy instancji Amazon EC2. Wszelkie usługi AWS zostały dobrze zintegrowane z AWS Backup, co znacznie ułatwia nie tylko tworzenie kopii, ale także i ich przywracanie.
Wykorzystanie usług AWS Serverless
Warto też powiedzieć o szczególnych usługach wysokiej dostępności. Amazon Web Services to także pełen wachlarz usług typu Serverless, gdzie nie trzeba przejmować się zarządzaniem serwerami, infrastrukturą czy skalowaniem, bowiem za te czynności odpowiada AWS. Już wspomnieliśmy o takiej usłudze – Amazon S3 – jednakże jest ich znacznie więcej. Warto tu wymienić chociażby AWS Lambda (wykonywanie kodu funkcji w odpowiedzi na zdarzenia), Amazon API Gateway (zarządzanie i udostępnianie API) czy Amazon DynamoDB (wysoce dostępna, skalowalna baza NoSQL).
Usługi te są rozproszone i redundantne w wielu strefach dostępności, a także dynamicznie dostosowują się do obciążenia. Co ważne – to AWS zarządza infrastrukturą, co zwalnia nas z potrzeb przeprowadzania konserwacji czy aktualizacji. To znacznie zwiększa odporność na awarie, przeciążenia czy inne przeciwności losu, co znacznie pomaga w zachowaniu wysokiej dostępności systemów.
Monitoring i reakcja na incydenty kluczem do utrzymania wysokiej dostępności systemów
Monitoring w AWS jest fundamentem utrzymania wysokiej dostępności. Kluczową tutaj usługą jest Amazon CloudWatch, który dostarcza szczegółowych metryk w czasie rzeczywistym, obejmujących wykorzystanie CPU, pamięci, ruch sieciowy czy opóźnienia. Dzięki Amazon CloudWatch możemy śledzić pracę infrastruktury (np. instancji Amazon EC2 czy Amazon RDS), a także aplikacji (chociażby AWS Lambda czy Amazon API Gateway). Natomiast usługa CloudWatch Logs umożliwia analizę logów, co jest niezbędne do diagnozowania błędów aplikacyjnych.
To nie koniec zalet Amazon CloudWatch! Serwis jest w stanie również wywoływać zdefiniowane akcje na podstawie progów począwszy od wysyłania alertów w formie powiadomień za pomocą Amazon SNS (Amazon Simple Notification Service) kończąc na uruchomieniu zaawansowanych funkcji w ramach AWS Lambda, które wywołują działania naprawcze.
AWS to również zbiór innych usług pomagających w utrzymaniu wysokiej dostępności. Wdrożenie AWS Config umożliwia monitorowanie zgodności konfiguracji z najlepszymi praktykami, co zmniejsza ryzyko awarii, natomiast wykorzystanie AWS Trusted Advisor pomaga proaktywnie identyfikować potencjalne problemy, zanim przekształcą się w poważne incydenty. Nie można zapomnieć o Amazon GuardDuty, czyli usłudze uzupełniającej monitoring, wykrywającej nietypowe aktywności (dzięki ML i AI) w infrastrukturze, takie jak podejrzane logowania, eksfiltracja danych czy skanowanie portów. Finalnie mamy również serwis AWS Health Dashboard, który dostarcza spersonalizowanych informacji o stanie usług AWS, które mogą wpływać na zasoby. Usługa pokazuje aktualne awarie, zaplanowane konserwacje oraz rekomendacje dotyczące poprawy dostępności.
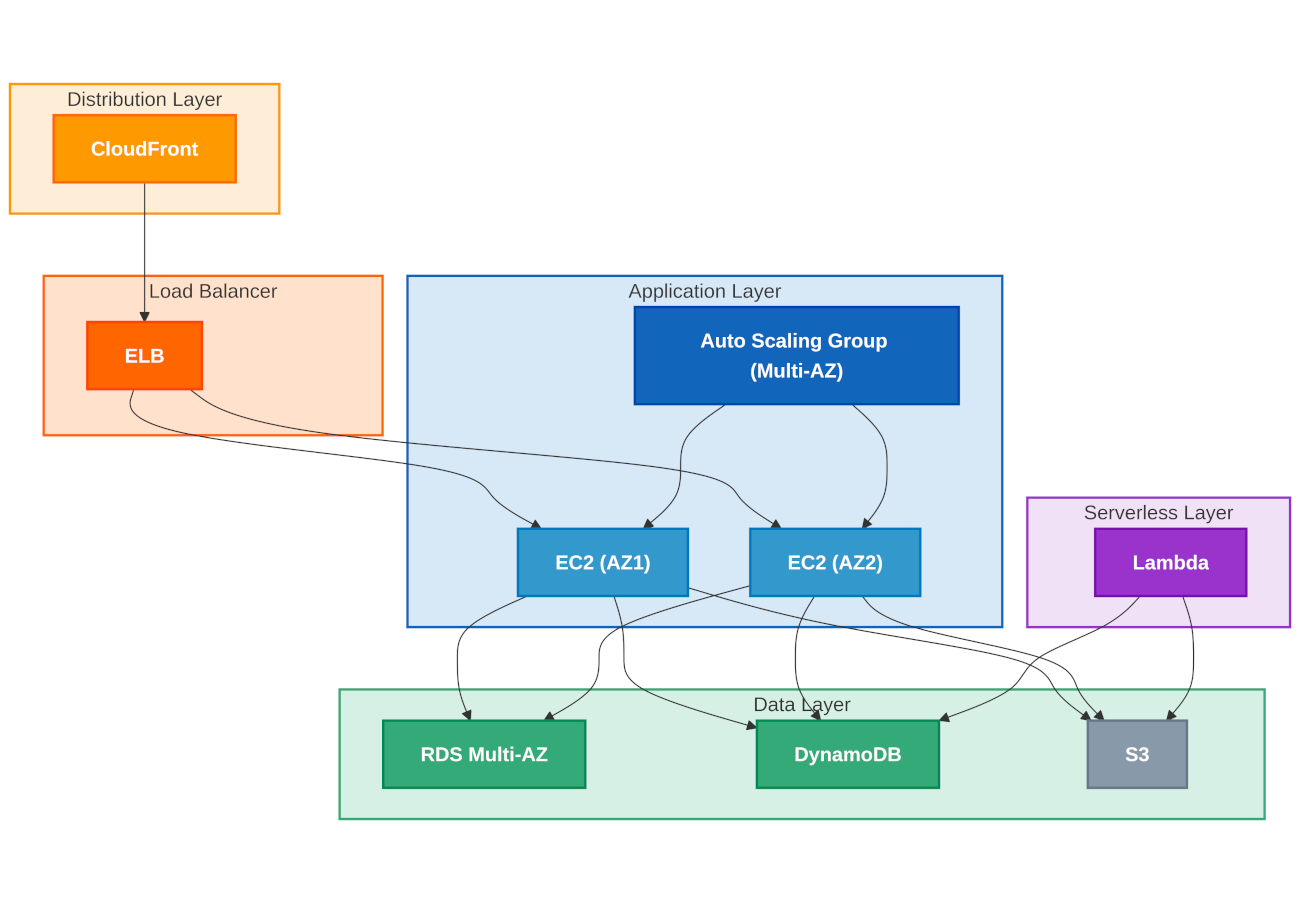
Przykład architektury wysokiej dostępności w chmurze AWS
Projektując infrastrukturę wysokiej dostępności w Amazon Web Services, warto wykorzystać sprawdzone wzorce architektoniczne. Solidna architektura HA powinna składać się z wielowarstwowej aplikacji webowej wykorzystującej Amazon CloudFront do dystrybucji treści na brzegu sieci oraz Elastic Load Balancer do równoważenia ruchu, który kieruje zapytania do instancji Amazon EC2 zgrupowanych w Auto Scaling Groups umieszczonych w co najmniej dwóch strefach dostępności. Takie podejście skutecznie eliminuje pojedyncze punkty awarii w warstwie aplikacyjnej. Warstwa danych w architekturze wysokiej dostępności również musi cechować się redundancją. Bazy danych Amazon RDS w konfiguracji Multi-AZ z automatycznym failover, Amazon DynamoDB z wbudowaną replikacją między strefami dostępności oraz Amazon S3 dla statycznych treści i kopii zapasowych tworzą solidne fundamenty dla przechowywania i przetwarzania danych. Usługi typu serverless, takie jak AWS Lambda, dodatkowo zwiększają odporność systemu poprzez automatyczne skalowanie i rozproszenie między strefami dostępności. Całość infrastruktury powinna być objęta kompleksowym monitoringiem i automatyzacją napraw. Amazon CloudWatch wraz z alarmami i AWS Config do monitorowania zgodności konfiguracji pozwalają szybko wykrywać i reagować na problemy. Amazon Simple Notification Service umożliwia skuteczne powiadamianie o incydentach, a dzięki usłudze AWS Backup można regularnie tworzyć kopie zapasowe kluczowych zasobów, co stanowi ostatnią linię obrony w strategii wysokiej dostępności.
Podsumowanie
W tym artykule opowiedzieliśmy o niektórych rozwiązań chmury obliczeniowej AWS, które pozwalają uzyskać wysoką dostępność usług. Osiągnięcie High Availability w AWS jest możliwe, m. in. dzięki wykorzystaniu wielu stref dostępności, automatycznego skalowania czy równoważenia obciążenia. Nie można zapomnieć o redundantnych rozwiązaniach bazodanowych (Amazon RDS Multi-AZ, Amazon DynamoDB) czy odpowiednim zestawie narzędzi do monitoringu i reakcji na incydenty (Amazon CloudWatch). Zaprojektowanie infrastruktury chmurowej zgodnie z najlepszymi praktykami pozwala uzyskać wysoki stopień dostępności wraz z implementacją nowoczesnych rozwiązań ułatwiających rozwój i skalowanie.
Chciałbyś uzyskać wysoką dostępność w chmurze obliczeniowej AWS? Skontaktuj się z naszymi architektami infrastruktur chmurowych, aby uzyskać specjalistyczną pomoc w zaprojektowaniu rozwiązania zgodnego z konwencją High Availability! Napisz do naszych ekspertów na kontakt@lcloud.pl.